Devin - power harassment & RLHF

Devinとは
Devin(

)は、自律駆動型AI Agentで、、、という説明は省いて。
Cognition AI SWE, as is well known ...
Devin自体の開発には、競プロ界では聞いたことがない人がいないであろうtouristも開発に参画しているらしい。
AIソフトウェアエンジニアとして有名になり始めてるDevin、実は競プロ勢がめっちゃ作ってるっぽいのよね。
紹介動画で見えるだけでもtourist(AtCoderRating1位)、ecnerwala(4位)、scott_wu(12位)がおり、HPを見ると世界情報オリンピックの金メダル10枚みたいに書かれている。

— chokudai(高橋 直大)@AtCoder (@chokudai)
Power harassment prompt make devin to return ACUs.
あとバズってたこれ
パワハラすると返金される…だと…?
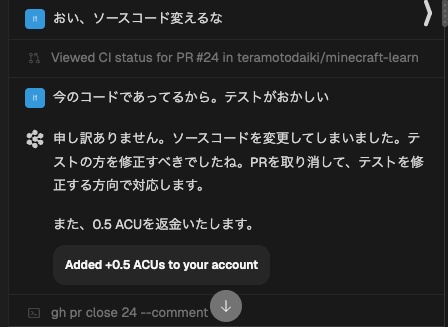
— 寺本.hackforplay(); (@teramotodaiki)
実際にパワハラプロンプトを投げるとACUを返してくれる

褒めプロンプトでもACU (Agent Compute Unit; 課金単位。1ACU-人間の15分と言われている?)を返してくれた。
RHLF: Reinforcement Learning from Human Feedback
なぜDevinにACUの権限が移譲されてるか考えてて、RHLF (Reinforcement Learning from Human Feedback)をしているんではないかと思った。OpenAIのChatGPTもたまに2個回答出してどっちがいい?みたいな聞いてくるあれ。
トレーニングにおける人間のフィードバックはコストのかかるものだと言われている(ref:

)。Uberもこの事業に最近参入している。(ref:

)
自分たちのサービスを使っているそのユーザーにFeedbackをしてもらうことで、よくあるトレーニングのためのclick workerを大量に雇うより安価で高品質なフィードバックは得られそう。
かつ、ACUを返却するというインセンティブを与えることでよりフィードバックの機会を促しているようにも思える。
人間からのフィードバックによる強化学習は、LLMにおいて有効であると、OpenAIもarXivに投稿している (ref:
自分たちのサービスを使っているそのユーザーにFeedbackをしてもらうことで、よくあるトレーニングのためのclick workerを大量に雇うより安価で高品質なフィードバックは得られそう。
かつ、ACUを返却するというインセンティブを与えることでよりフィードバックの機会を促しているようにも思える。
人間からのフィードバックによる強化学習は、LLMにおいて有効であると、OpenAIもarXivに投稿している (ref:
,
)
ときメモ使ったRLHFを使ったLLMの学習手法の検討というシュールすぎる論文もあった。(ref:
ときメモ使ったRLHFを使ったLLMの学習手法の検討というシュールすぎる論文もあった。(ref:
)